一次程序宕机的辛酸追寻之路
【前言】 如果你是工程师,你能够从下面的过程中学习到众多技能、思路和解决问题的办法,当然顺便鄙视下[前任]工程师; 如果你是测试工程师,你会发现很多问题是我们难以模拟和测试的,更困难的是我们很难想到这些问题,当然顺便羞辱下[提测]工程师; 如果你是管理者,你会想到代码检查/复查/重构是多么的重要,更重要的是要有思想上的觉悟,当然顺便体谅下[加班]工程师; 如果你是运维工程师,我想说“事出必有因”,即使寻找问题的道路很艰难和痛苦,更无人知晓,但[千万别放弃]; ……不想夸张了……
【开篇上】大约[15:00]
云 X 来找我说管理后台宕机了[admin-web],没找到原因,主服务机器 sky1 重启了,备机 db1 还不能正常提供服务。 通常遇到这种情况,Java 程序的标准做法是:
- jstat 查询内存使用率 -> 正常
- jstack 查询线程栈状况 -> 大约正常,只有一个看起来像是错误的问题
- jmap 查看内存状况 -> 正常
- log4j 日志文件 -> 基本正常(事实上不正常,只是未发现)
- gc 日志文件 -> 备机看到一堆内存分配失败
- sql 记录文件 -> 正常
- jetty 的日志文件 -> 大致正常
这时候一般会比较灰心,因为已经没有主机的现场了,如果没有发现明显的错误,一般是比较崩溃的, 找问题也是比较艰辛的。
云 X 还怀疑是机房的问题。我通过
curl –I 'http://127.0.0.1:8082' -H 'Host:c.xxx.com'
发现有时候好,有时候坏,就觉得莫名其妙了。 不过既然有时候坏,说明不是网络和机器问题,剩下的只是程序问题。
这时候只能将日志文件一行行看了,尤其是 SQL 文件,Log4j 日志等,但收获有限。
【开篇下】大约[15:20]
再次说明下,我们有两台机器,主机器 sky1 和 被机器 db1。 由于主机器 sky1 上的服务已经重启,所以内存状况,线程状况,gc 状态都不在了, 虽然有一个当时的线程栈文件,但没有提供更多有用的线索。
现在有用的信息只能从各自日志文件中寻找了。 通过不断尝试,终于在 log4j 的日志文件中找到我们想要的关键字了:
org.springframework.web.util.NestedServletException: Handler processing failed; nested exception is java.lang.OutOfMemoryError: Java heap space
java.lang.RuntimeException: OOME with size 8
01-08 12:25:41:ERROR(32)qtp1690254271-21 ExceptionHandler -
org.eclipse.jetty.io.EofException
Caused by: java.io.IOException: 断开的管道
OOME,java.lang.OutOfMemoryError,最常见也是较难以处理的程序错误。 OOME 以后,很多程序的内存状态都不能很好恢复,比如 jetty 的连接就不能很好释放,所以会导致一部分死锁卡住。
这时候云 X 说是不是行程加载数据太多,导致内存用光了。
我把当前的内存栈都拿出来看看,【行程类】并没有发现异常,其它几个机器也看了下,都挺正常的。 也没有找到有用的线索。
事实上经过几次重构,现在【行程类】加载内存已经控制在一个合理的范围内了,对于 1G 以上的内存一般不会用满。 由于准 A 项目还有很多开发任务,我已经没有耐心继续跟进下去了,准备下次遇到的时候我再去抓现场。
中间还有一些修改 nginx 配置,减少一些日志干扰等事情,由于后来发现和问题无关,这里就不表了。
这样就送走了云 X。
【中篇上】大约[15:40]
过了一会,发现无法从刚才问题中恢复思路,所以还是想想到底是什么原因引起的。 继续追寻之路,事实上后面才是更痛苦的。
既然知道是 OOM,那么很显然一定会有内存慢慢变化的过程。 主机器 sky1 服务重启了,备机器 db1 还在,
sky1 机器上 admin-web.gc.0.default 还保留着信息,首先当然是先备份此文件。 慢慢看。
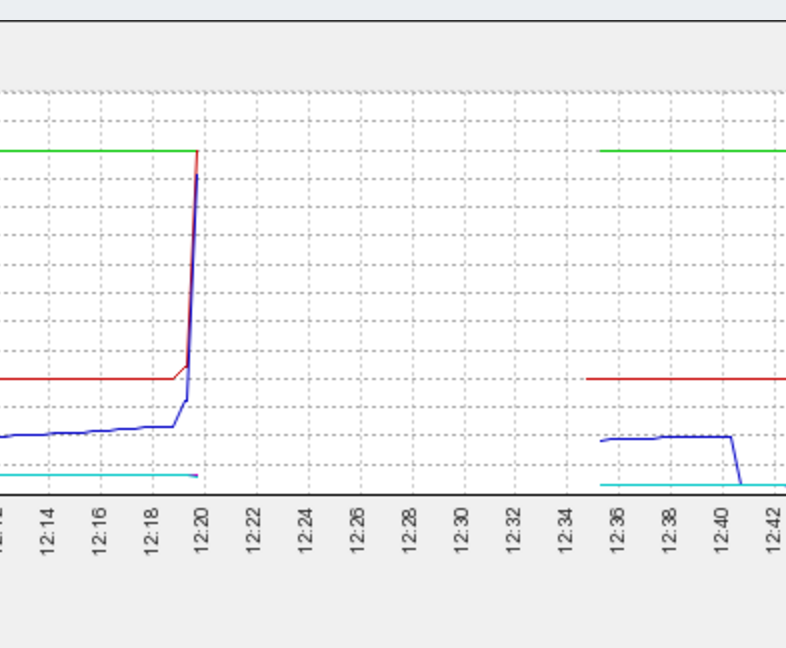
下图是查找问题的过程,一直到最后发现想要的结果。

事后看来这张图很有价值,只是当时深陷其中,没有很深入的思考。 首先可以看到 db1 这台机器上 11:58:38 有请求,很正常,内存申请 1024M,GC 回收 766M,还有 285M 紧接着下一个请求是 12:20:54 ,内存由 1024 释放到 604 从 12:20:56 开始,内存申请和占用持续增加,一直到 12:21:19 终于无法释放 Failure 失败了 由此可见,大约内存从 12:20:56 开始慢慢增加一直到 12:25:41 最终彻底 OOM 由于 GC 释放是一个滞后反应,所以日志中最终的结果是延后几分钟才奔溃:
01-08 12:25:41:ERROR(462)auditor_db1-1452149957746-633919db_watcher_executor ZookeeperConsumerConnector - error during syncedRebalance
java.lang.OutOfMemoryError: Java heap space
另外 sky1 机器上的日志有一些帮助(当时没发现),但更多的是干扰作用,比如:
01-08 12:17:29:INFO(41)runnerutils-1-thread-11 AppPushMsgUtil - push app message to :184180msg:{"push-data-type":"task-msg","alert":"有新任务啦!英国专属超级自由行快去抢吧","url":"http://m.xxx.com/task/list/"},cost time:20,resp:{"code":0,"msg":"发送消息成功"}
01-08 12:17:29:INFO(41)runnerutils-1-thread-11 AppPushMsgUtil - push app message to :52065msg:{"push-data-type":"task-msg","alert":"有新任务啦!英国专属超级自由行快去抢吧","url":"http://m.xxx.com/task/list/"},cost time:30,resp:{"code":0,"msg":"发送消息成功"}
01-08 12:17:30:INFO(41)runnerutils-1-thread-11 AppPushMsgUtil - push app message to :149669msg:{"push-data-type":"task-msg","alert":"有新任务啦!英国专属超级自由行快去抢吧","url":"http://m.xxx.com/task/list/"},cost time:34,resp:{"code":0,"msg":"发送消息成功"}
01-08 12:17:30:INFO(41)runnerutils-1-thread-11 AppPushMsgUtil - push app message to :32358msg:{"push-data-type":"task-msg","alert":"有新任务啦!英国专属超级自由行快去抢吧","url":"http://m.xxx.com/task/list/"},cost time:19,resp:{"code":0,"msg":"发送消息成功"}
01-08 12:17:30:INFO(41)runnerutils-1-thread-11 AppPushMsgUtil - push app message to :32358msg:{"push-data-type":"task-msg","alert":"有新任务啦!英国专属超级自由行快去抢吧","url":"http://m.xxx.com/task/list/"},cost time:19,resp:{"code":0,"msg":"发送消息成功"}
01-08 12:19:52:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:19:54:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (SyncConnected)
01-08 12:20:05:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:20:16:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Expired)
01-08 12:20:16:INFO(324)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - ZK expired; release old list of broker partitions for topics
01-08 12:20:16:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (SyncConnected)
01-08 12:20:16:INFO(169)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - read all brokers count: 2
01-08 12:20:16:INFO(174)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - Loading Broker 1.1.7.138-1426676227549:1.1.7.138:9092:true
01-08 12:20:16:INFO(174)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - Loading Broker 1.1.7.85-1426677889450:1.1.7.85:9092:true
01-08 12:20:26:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:20:35:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Expired)
01-08 12:20:35:INFO(324)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - ZK expired; release old list of broker partitions for topics
01-08 12:20:35:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (SyncConnected)
01-08 12:20:35:INFO(169)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - read all brokers count: 2
01-08 12:20:35:INFO(174)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - Loading Broker 1.1.7.138-1426676227549:1.1.7.138:9092:true
01-08 12:20:35:INFO(174)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - Loading Broker 1.1.7.85-1426677889450:1.1.7.85:9092:true
01-08 12:20:52:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:21:01:INFO(381)qtp1690254271-24-EventThread ZkClient - zookeeper state changed (Expired)
01-08 12:21:10:INFO(324)ZkClient-EventThread-4632-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181/xpower/jafka ZKBrokerPartitionInfo - ZK expired; release old list of broker partitions for topics
01-08 12:22:13:INFO(381)admin-consumers-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:23:03:INFO(381)admin-consumers-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:23:17:INFO(381)Thread-22-EventThread ZkClient - zookeeper state changed (Disconnected)
01-08 12:23:17:INFO(381)Thread-22-EventThread ZkClient - zookeeper state changed (Expired)
01-08 12:33:55:INFO(461)main DispatcherServlet - FrameworkServlet 'servlet': initialization started
01-08 12:33:55:INFO(513)main XmlWebApplicationContext - Refreshing WebApplicationContext for namespace 'servlet-servlet': startup date [Fri Jan 08 12:33:55 CST 2016]; root of context hierarchy
01-08 12:33:55:INFO(316)main XmlBeanDefinitionReader - Loading XML bean definitions from ServletContext resource [/WEB-INF/servlet-context.xml]
01-08 12:33:56:INFO(316)main XmlBeanDefinitionReader - Loading XML bean definitions from ServletContext resource [/WEB-INF/spring-quartz.xml]
01-08 12:33:57:INFO(69)ZkClient-EventThread-30-1.1.7.138:2181,1.1.8.231:2181,1.1.7.85:2181 ZkEventThread - Starting ZkClient event thread.
01-08 12:33:57:INFO(381)main-EventThread ZkClient - zookeeper state changed (SyncConnected)
AppPushMsgUtil 有一些干扰效果,查看代码并没有发现问题,当然最后也是不因为此引起的。 ZkClient 的日志从 12:19:52 前就不正常,一直到 12:33:55 重启都没能恢复过来,所以看起来系统应该是从 12:19:52 开始出问题的。
这时候剩下没有关注的日志只有 nginx 的 access_log 和 error_log 了,我们去看看。
从 front1/front2 开始,最终我们在 front1 的日志中发现一条异常日志:
2016/01/08 12:21:19 [error] 2103#0: *3529201742 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.255.252.2, server: c.xxx.com, request: "GET /privacy/crm/user/?uid=%7Bxxxx HTTP/1.1", upstream: "http://1.1.19.158:8082/privacy/crm/user/?uid=%7Bxxxx", host: "c.xxx.com"
有意思的是日志中的时间是 12:21:19,和我猜想的错误时间 12:19:52 不大一致,有点矛盾。 access_log 中 12 点左右的日志异常是:
[root@front1 tmp]# awk '{if($(NF-5)>0.1){print $0}}' /opt/logs/nginx/c.admin.access.log
"124.65.117.214" c.xxx.com - [08/Jan/2016:12:24:34 +0800] "GET /pack/update-coop-info/?packageId=1256 HTTP/1.1" 502 0 "-" "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "10.255.252.2" "240.002" "120.001, 120.001 : 0.000" "1.1.19.158:8082, 1.1.6.125:8082 : admin-web" - - 974d45ccbfa8668acf8574a530c81427-sA sA
"114.242.69.123" c.xxx.com - [08/Jan/2016:12:25:41 +0800] "GET /privacy/crm/user/?uid=%7Bxxxx HTTP/1.1" 504 0 "-" "Mozilla/5.0 (Macintxxh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36" "10.255.252.2" "382.022" "120.002, 120.001 : 120.000, 22.019" "1.1.19.158:8082, 1.1.6.125:8082 : 1.1.19.158:8082, 1.1.6.125:8082" - - 69b8c0ab86bac34202b3aaafe3a61ee6-63Z 63Z
"124.65.117.214" c.xxx.com - [08/Jan/2016:12:26:04 +0800] "GET /advisor/1016657/?ref=sales HTTP/1.1" 502 0 "-" "Mozilla/5.0 (Macintxxh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17" "10.255.252.2" "240.002" "120.001, 0.000 : 120.001, 0.000" "1.1.19.158:8082, admin-web : 1.1.19.158:8082, admin-web" - - 48829b80937282485a9355500243730a-IKT IKT
时间都是在 12:25 分附近,这很奇怪。 但看到用户登录,并且有 IP,就随机查询一个看看。当时查询的是:114.242.69.123。 结果让我很兴奋 [这玩意儿真 NB]。
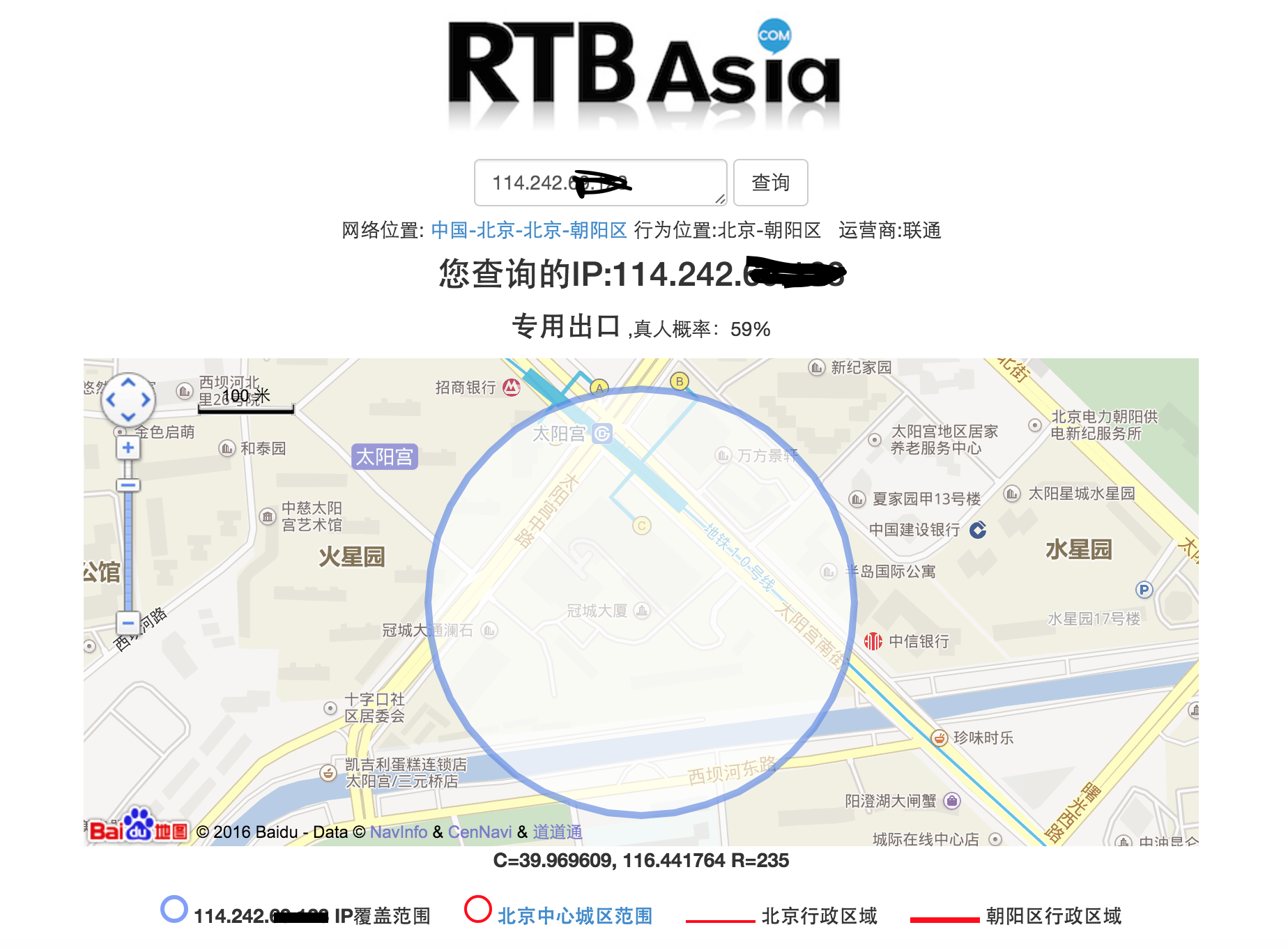
既然是同事,那么我就看看是谁,然后收集些信息。
 查询下后台:
查询下后台:
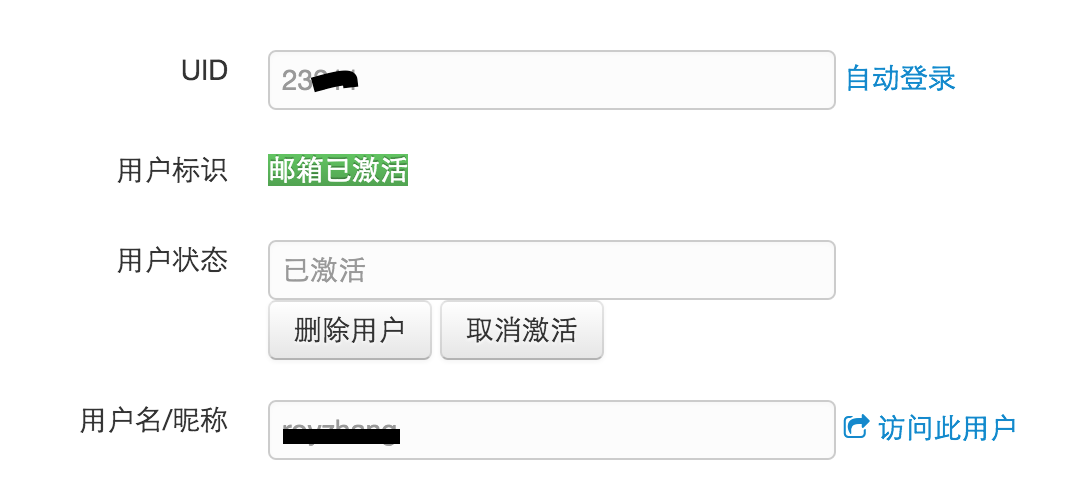 发现居然是 Rxx,于是就问问他,以下是对话:
发现居然是 Rxx,于是就问问他,以下是对话:
我 16:02:51
"114.242.69.123" c.xxx.com - [08/Jan/2016:12:25:41 +0800] "GET /privacy/crm/user/?uid=%7Bxxxx HTTP/1.1" 504 0 "-" "Mozilla/5.0 (Macintxxh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36" "10.255.252.2" "382.022" "120.002, 120.001 : 120.000, 22.019" "1.1.19.158:8082, 1.1.6.125:8082 : 1.1.19.158:8082, 1.1.6.125:8082" - - 69b8c0ab86bac34202b3aaafe3a61ee6-63Z 63Z
我 16:03:03
中文12:25 是你访问的? [中文应当是中午,手误]
张Sir 16:03:28
是,jordan给我发的链接
张Sir 16:03:53
有问题?
我 16:03:56
然后你访问下 把我们机器搞死啦?
我 16:04:02
当时应该是打不开吧?
张Sir 16:04:01
啊?
张Sir 16:04:10
是啊
张Sir 16:04:19
我还以为网挂了
张Sir 16:05:00
张Sir 16:05:11
是个坑吗?
我 16:06:49
不知道 但是第一个错误 确实是从这里开始的
张Sir 16:07:27
{}嵌套了吗?
张Sir 16:08:12
好怕啊,我需要畏罪潜逃吗?
我 16:09:16
其实我没找到原因
张Sir 16:11:06
uid参数不识别除了int 以外的类型?
张Sir 16:28:51
我想起来了,当时是这样
张Sir 16:31:29
以前点过这个链接,并没问题。后来,mars用他账号在我电脑登录CRM查了些别的,后来我又点这个链接,但是进入了登录页面。用我账号登录后自动重定向到这个链接,然后挂了。后来我点开新的窗口进,就正常了
我 16:33:34
不懂 好神奇啊
张Sir 16:34:37
情况就是,换了俩账号点这个链接,前一个是没权限的,后一个被重定向过来的
张Sir 16:35:05
我如果不潜逃,是不是可以得查BUG大奖?
我 16:35:33
如果你能帮助找到bug 可得之
张Sir 16:35:57
听上去,还是得潜逃
张Sir 16:38:29
估计是uid={XXX}这个,程序并没有校验
我 16:42:31
我看了代码 这个参数有处理
我 16:42:45
其实我想说的是 出问题的时候居然刚好是你访问的时候 太巧合了
张Sir 16:46:13
阴差阳错啊
我看了代码,事实上 RequestUtils.geInt 函数是我写的,因此并不会导致问题,更不会导致 OOM。

没有得到我想要的答案,我继续陷于了深深的沉思中。
事实上,我已经准备放弃了。
【中篇下】[大约 16:50 分]
就在我准备放弃的时候,我灵机一想,如果是 OOM,要么是定时任务,要么是数据库读取数据太多(这个比较常见,因为只有数据库中才有那么多的数据)。 定时任务看不到,数据库访问的 sql.log 文件中没有,会不会是某个人使用《事务》操作 Connection 导致的呢?
因为操作 Connection 我并不能拿到执行的 SQL 语句,所以通常不知道执行时间,sql.log 中当然不会有。 但我想到了 mysql.slowlog. 于是去数据库中查询。
mysql> select * from slow_log where start_time > '2016-01-08 11:30' limit 10\G
*************************** 1. row ***************************
start_time: 2016-01-08 12:05:19
user_host: messaging[messaging] @ [1.1.19.158]
query_time: 00:00:11
lock_time: 00:00:00
rows_sent: 1
rows_examined: 1727769
db: messaging
last_insert_id: 0
insert_id: 0
server_id: 168166858
sql_text: SELECT count(*) FROM message WHERE 1 and sender = 277376
*************************** 2. row ***************************
start_time: 2016-01-08 12:19:42
user_host: txx[txx] @ [1.1.19.158]
query_time: 00:00:22
lock_time: 00:00:00
rows_sent: 1756890
rows_examined: 1756890
db: compass
last_insert_id: 0
insert_id: 0
server_id: 168166858
sql_text: select * from advisor_travel_session where uid=0 order by created_at desc
*************************** 3. row ***************************
start_time: 2016-01-08 12:19:42
user_host: txx[txx] @ [1.1.19.158]
query_time: 00:00:49
lock_time: 00:00:00
rows_sent: 1756890
rows_examined: 1756890
db: compass
last_insert_id: 0
insert_id: 0
server_id: 168166858
sql_text: select * from advisor_travel_session where uid=0 order by created_at desc
*************************** 4. row ***************************
start_time: 2016-01-08 12:21:08
user_host: txx[txx] @ [1.1.6.125]
query_time: 00:00:15
lock_time: 00:00:00
rows_sent: 1756898
rows_examined: 1756898
db: compass
last_insert_id: 0
insert_id: 0
server_id: 168166858
sql_text: select * from advisor_travel_session where uid=0 order by created_at desc
*************************** 5. row ***************************
start_time: 2016-01-08 12:25:03
user_host: txx[txx] @ [1.1.6.125]
query_time: 00:03:44
lock_time: 00:00:00
rows_sent: 227487
rows_examined: 227487
db: compass
last_insert_id: 0
insert_id: 0
server_id: 168166858
sql_text: select * from advisor_travel_session where uid=0 order by created_at desc
看到 rows_sent: 1756890 这一行我就什么都明白了,什么都明白了,都明白了,明白了,白了,了……
网站允许游客提小帮手,由于没有登录,所以用户 uid=0,而我们去查一个用户 uid=0 的小帮手,结果帮 3 年累计的小帮手全查出来了。 数据有 175 万啊,兄弟姐妹们,175 万啊。 这是什么概念?将近一千万啊,一千万数据放内存中,能不爆么? 关键是还查询了 4 次,4 次是什么概念? 4 次我都有 杀死 [前任] 程序员的冲动!!!
当然很兴奋的和 Roy 同学说了。
我 16:52:01
我靠,还真是你引起的!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
张Sir 16:52:27
我已经打包跑路了
张Sir 16:53:32
咋回事?
我 16:54:22
前一分钟真的准备放弃不查询了 结果居然让我找到问题了!!
张Sir 16:54:42
啥问题?
我 16:55:40
大意就是 游客可以留小帮手 由于没登录 所以uid=0
而你访问的那个链接 是一个不合法的uid,解析错误会当做0 而数据库中有数十万uid=0的小帮手
结果全部查询出来放内存中
内存爆了!!!!
张Sir 16:56:01
啊,没有limit ?
我 16:56:20
所以说 ----> 锉
我 16:56:36
public List<AdvisorTravelSession> queryTravelSessionsByUid(int uid) {
String sql = "select * from advisor_travel_session where uid=? order by created_at desc";
return dao.queryList(new DefaultOpList<AdvisorTravelSession>(sql, bizName, new AdvisorTravelSessionMapper()).addParams(uid));
}
public List<AdvisorTravelSession> queryTravelSessionsByUid(int uid,int limit) {
String sql = "select * from advisor_travel_session where uid=? order by created_at desc limit ? ";
return dao.queryList(new DefaultOpList<AdvisorTravelSession>(sql, bizName, new AdvisorTravelSessionMapper()).addParams(uid,limit));
}
我 16:56:50
其实有两个方法 只是用成第一个了
我 16:57:00
当然事实上 第一个也确实不应当存在!
我 16:57:16
哎 @xxx 哥跑路了 我想砍他
张Sir 16:57:16
开始我也想是没有limit, 后来觉得不可能这么弱
张Sir 16:57:41
哦,xx大拿的。那就不奇怪了
张Sir 16:59:54
大拿的思维果然异于常人,挖坑都用这么个奇怪的逻辑
我 17:02:59
我操 查询了无数的数据 累死了
【下篇上】 [大约 17:03]
既然找到问题了,动手修改就很容易了。
事实上有两个方法(见上面 QQ 聊天),所以我将第一个方法重定向到第二个方法上,同时强制使用 limit=10。 另外为了防止游客查询 uid=0 出来的数据错误,在第二个方法中判断 uid<=0 是返回空列表。 因为游客实际上是根据 tsid(小帮手主键 id)来查询的,并不是根据 uid 来查询的。
这样问题就得到了解决。 但解决这样,显然是不满足的。
【下篇中】[大约 17:10]
接下里我想做的是,将所有 SQL 查询记录下来,不仅包括时间还是可能的结果集条数和更新数量。
/** _ 记录 SQL 语句执行状况 _ @param begin 此次查询的开始时间(unix 毫秒) _ @param op 操作符 _ @param rownum 结果行数或者受影响记录行数 */ private void endLog(long begin, Op op, int rownum) { if (begin > 0) { log.debug(format(“SQL_EXECUTE#%s#%s#%s#%d#%d”, op.bizName, op.getRoutePattern(), op.sql, (System.currentTimeMillis() - begin), rownum)); } }
这就需要修改大量的代码,因为以前未曾想过记录数和行数,而且也不容易。 总之修改大量的代码后基本上除了 Connection/Transation 这类无法记录的情况下, 其它都可以记录 SQL 执行的时间和行数。@seven 可看看是否受此影响。 例如上线后现在的结果:
tac sql.log|grep SQL_EXECUTE|awk -F'#' '{if($NF>100){print $0}}'|head
01-08 19:49:48:DEBUG(73)qtp1690254271-23 IDao - SQL_EXECUTE#compass#compass#select * from poas_review where pid in (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)#11#219
01-08 19:49:15:DEBUG(73)qtp1690254271-25 IDao - SQL_EXECUTE#admin#admin#select path,pathdesc from aclresources order by path#1#193
01-08 19:49:15:DEBUG(73)qtp1690254271-25 IDao - SQL_EXECUTE#admin#admin#select * from users where status=0 order by username#3#196
可以看到这几个 SQL 语句执行的条数分别为 219,193,196,但是时间还算很快,除了 poas_review 这个表本身字段很多和解析困难之外。
【下篇下】[19:52]
我会说整理这封邮件花了我 2 个小时么?2 个小时么?(所有现场都需要重新重复一遍,并记录下来)
所以下面是谈谈结论时间: 所有查询类 SQL 必须有 limit 的,除非有明确的主键查询(明知道结果是 1 条),不然不能保证未来是否修改条件从而爆表! 应当正确使用 Dao 操作,严格使用 Connection/Transaction 等来直接操作数据库,这样无法记录 SQL 语句和执行时间以及影响条数! 输入参数应当尽可能的保证安全,不要信任外界输入。 最后既然是个问题,千万别放弃,搞明白才是最重要的。要有一个探索未来的心! 如果在 DAO 层增加 limit 或者 uid<=0 判断,都不会引起此问题。
如果你还关心问题,解释下上面日志时间问题:
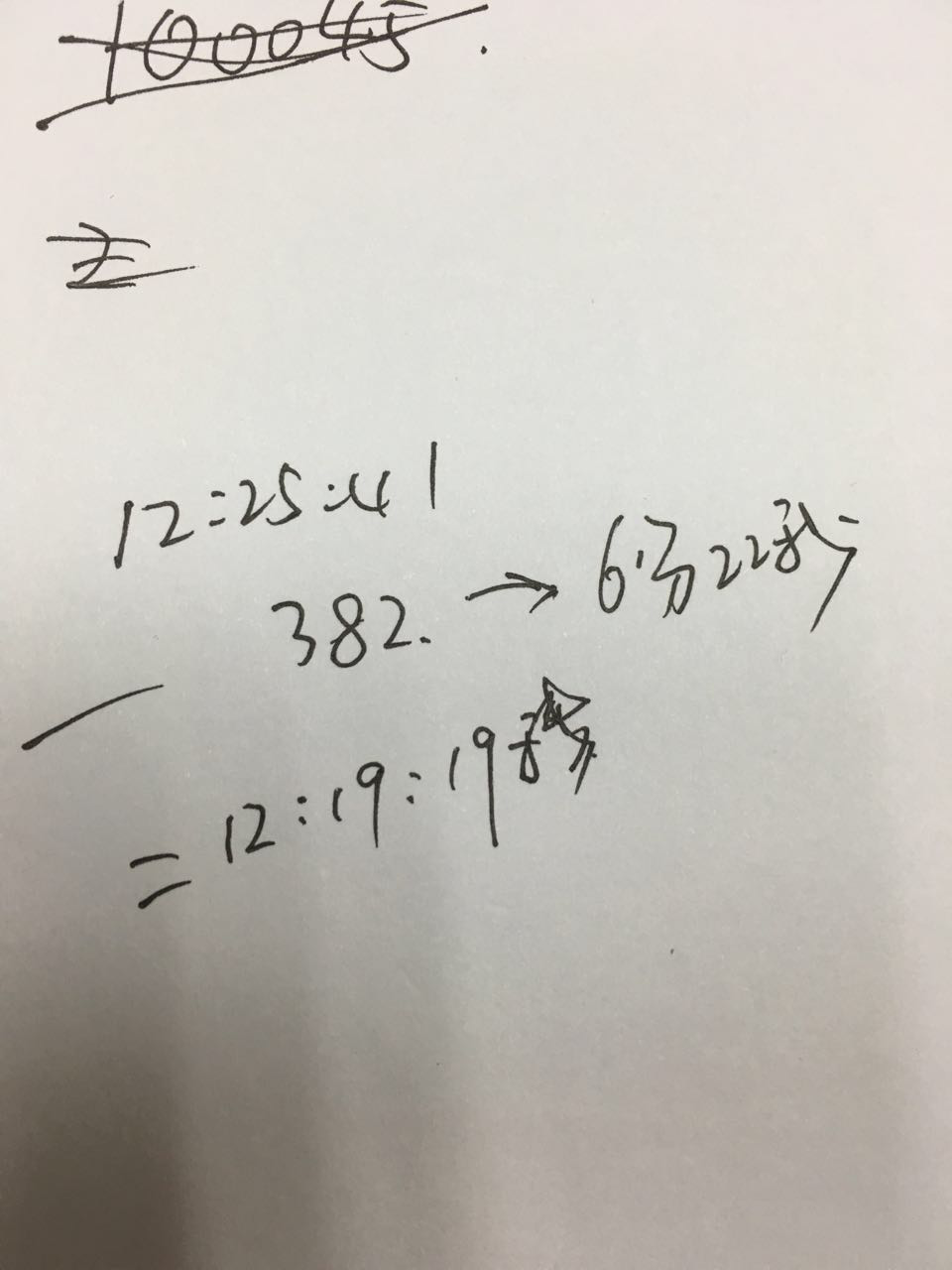
"114.242.xx.xxx" c.xxx.com - [08/Jan/2016:12:25:41 +0800] "GET /privacy/crm/user/?uid=%7Bxxxx HTTP/1.1" 504 0 "-" "Mozilla/5.0 (Macintxxh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36" "10.255.252.2" "382.022" "120.002, 120.001 : 120.000, 22.019" "1.1.19.158:8082, 1.1.6.125:8082 : 1.1.19.158:8082, 1.1.6.125:8082" - - 69b8c0ab86bac34202b3aaafe3a61ee6-63Z 63Z
有此可见问题大约发生于 12:19:19 秒附近,这和前面推导的 ZkClient 的日志从 12:19:52 前就不正常,一直到 12:33:55 重启都没能恢复过来,所以看起来系统应该是从 12:19:52 开始出问题的。 是一致的。 这与 zabbix 也是吻合的。
一言难尽] . . . . . .
最后,我最近看了《神探狄仁杰》第二部,虽然是柯南式骗人手法,但是弄明白真相却是提升自己的良好机会。